
Partial-content web crawling using Go and HTTP/2
Reduce traffic and improve speed using streamed parsing

When I scraped a few thousand video descriptions, my Oxylabs proxy bill got me thinking:
The web application, which shall not be named, stores it’s video description in the <head> section of their document, alongside of OpenGraph and other high-entropy, machine readable metadata.
Everything that I need is inside that section, the first 100KB, the remaining 900KB are just dead weight.
If I could find a way to GET a URL, and abort the request when I got everything I needed I could save 90%* on my billable traffic, my billable compute time, and available bandwidth.
The potential
The <head> section of a HTML document (on web apps with good SEO) contains a lot of interesting metadata on the document.
For e-commerce stores it may contain Product objects, VideoObject for YouTube, DiscussionForumPosting for online-boards, et cetera.
I calculated the average size of the <head>, <body> and everything after </body> using a 2026 CommonCrawl WARC containing 28k+ HTML files from all over the web.
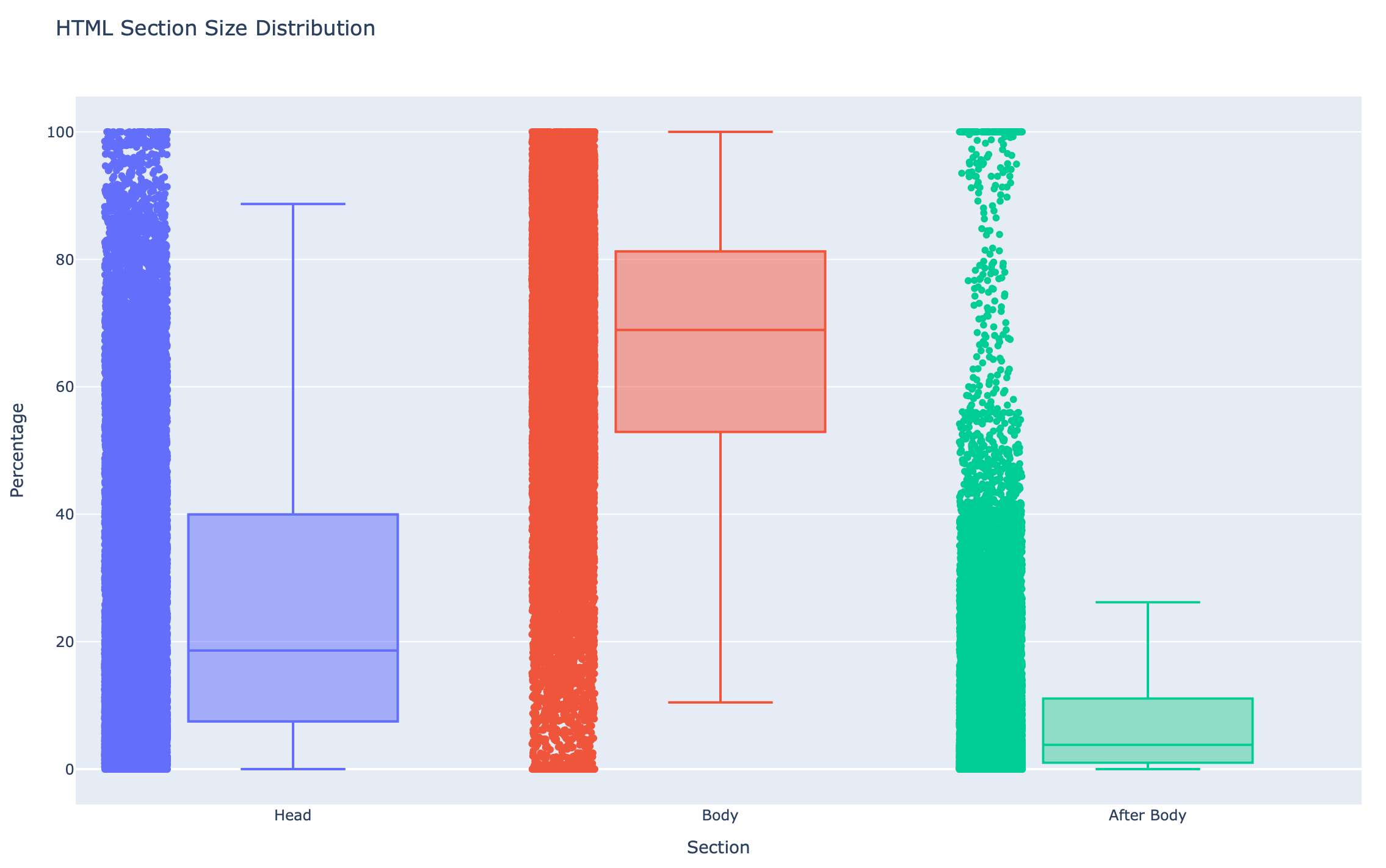
On average, the head section accounts for only 20% of the total Content-Length.
But keep in mind that this technique is not only applicable for retrieving the head section of a HTML document, you could also use it to
match a custom condition, like a XPath selector which when matched aborts the connection.
calculate a rolling SimHash to determine if the document has changed since our last crawl, without crawling the full document again.
blindly skip everything after the
</body>, if you are only extracting content from the body section (and not running a full browser).
And if you crawl millions of pages a day, the impact on your
proxy bill
crawler speed
Spark bytes read/written, Hadoop bytes read/written …
will be quite significant.
System design
For an ordinary GET request in HTTP 1.1 you need to open a TCP socket, negotiate your TLS, send your request, and read back your incoming data.
While it is very well possible to create a GET request with a custom DialContext, read the streamed response and .close() the underlying net.Conn (as seen here) this is a bad idea because:
HTTP 1.1 does not support pre-maturely aborting requests, you will trigger a lot of “Connection reset by peer” errors on your target web apps.
You need to perform the three-way handshake again, and again and again, this will offset your efficiency gains in some way or the other.
Packets which are still in-transit after you have closed your connection will be undeliverable and unacknowledged, upsetting your kernel and/or cloud provider and your target web app once again.
netstat -s | grep -i tcp
HTTP/2 to the rescue
HTTP/2 enables you to
send more than one request over one TLS connection, without having to re-negotiate and re-handshake.
send multiple requests at once (typically 100), separated into distinct streams.
prematurely terminate requests via the RST_STREAM frame 🎉🥳.
Let’s look at a HTTP/2 GET request in a sequence diagram:

A GET request is started by the client sending HeadersFrame with the requested resource path. Every frame in HTTP/2 has a numeric stream identifier (31 bit unsigned integer), 0x0 is reserved for identifying the whole connection.
The server sends n DataFrame’s, containing SETTINGS_MAX_FRAME_SIZE bytes of the full server response. The last DataFrame is marked with the END_STREAM (0x1) flag.
A stream can be closed by sending the aforementioned RST_STREAM frame, or the entire connection can be teared down using the GOAWAY frame.
Solution Design
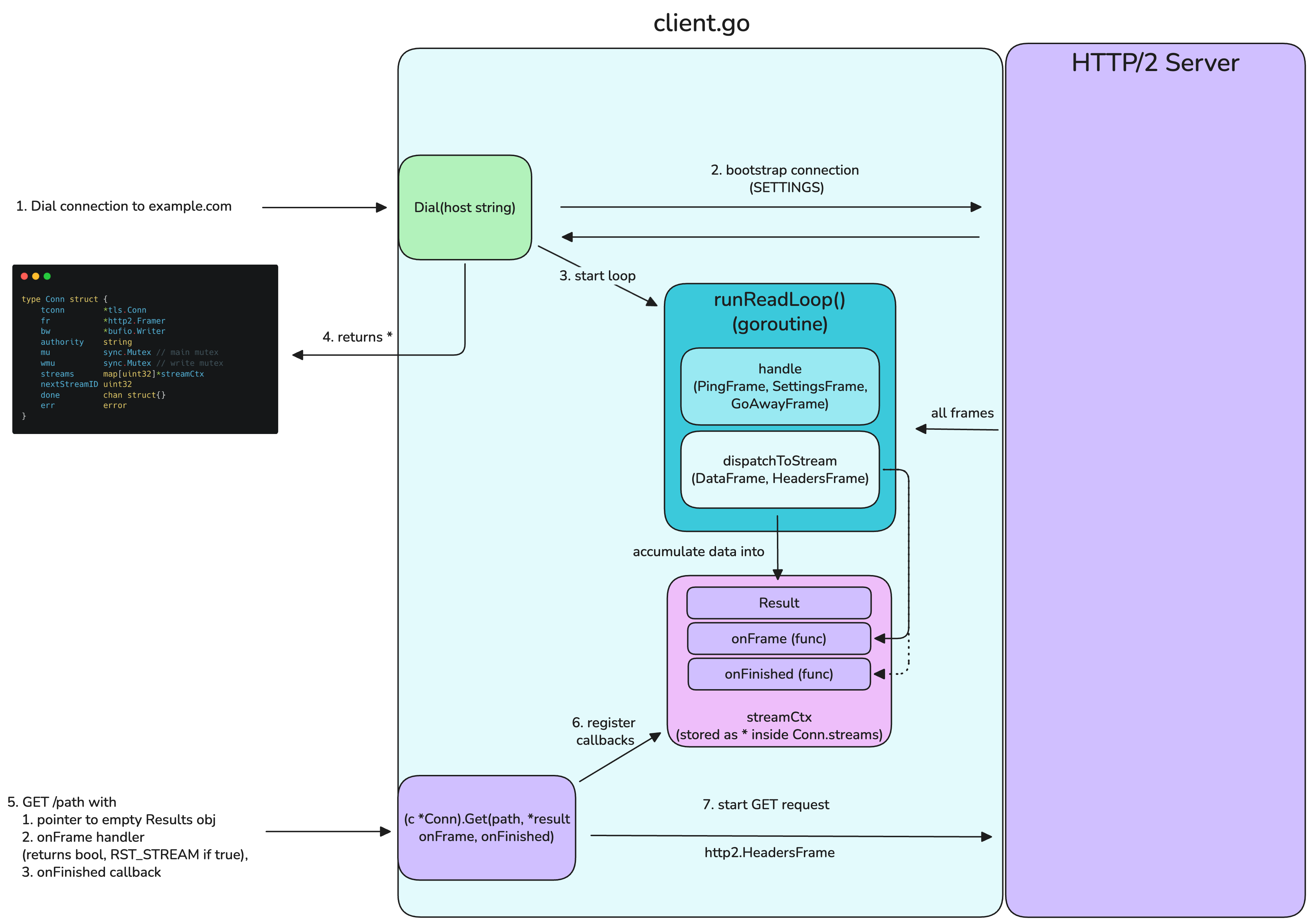
To achieve thread-safety but also easy maintain- and extendability I came up with this asynchronous, callback-based architecture.
Tl;dr the Dial method bootstrap a connection to the target server, starts a Goroutine which handles all inbound frames. At first all frames shall have a streamIdentifier of 0x0, because we did not open a new stream yet, these are handled internally by the Goroutine.
We open a new stream by calling the c.Get method, passing a
pointer to a empty Result obj
a function onFrame, which shall return True if a
RST_STREAMshall be triggereda callback onFinished, which let’s us know that our stream has ended and we can read the Result
The runReadLoop Goroutine then dispatches all frames tagged with the streamId of our .Get operation to their respective callbacks, and accumulates the DataFrame payload into our Result obj (the requested Path, err’s are also written there).
206 - Partial Content 🎉
And after some work of my very helpful assistant, I can crawl the <head> of my previous 250KB blog post with only 16KB of traffic used!
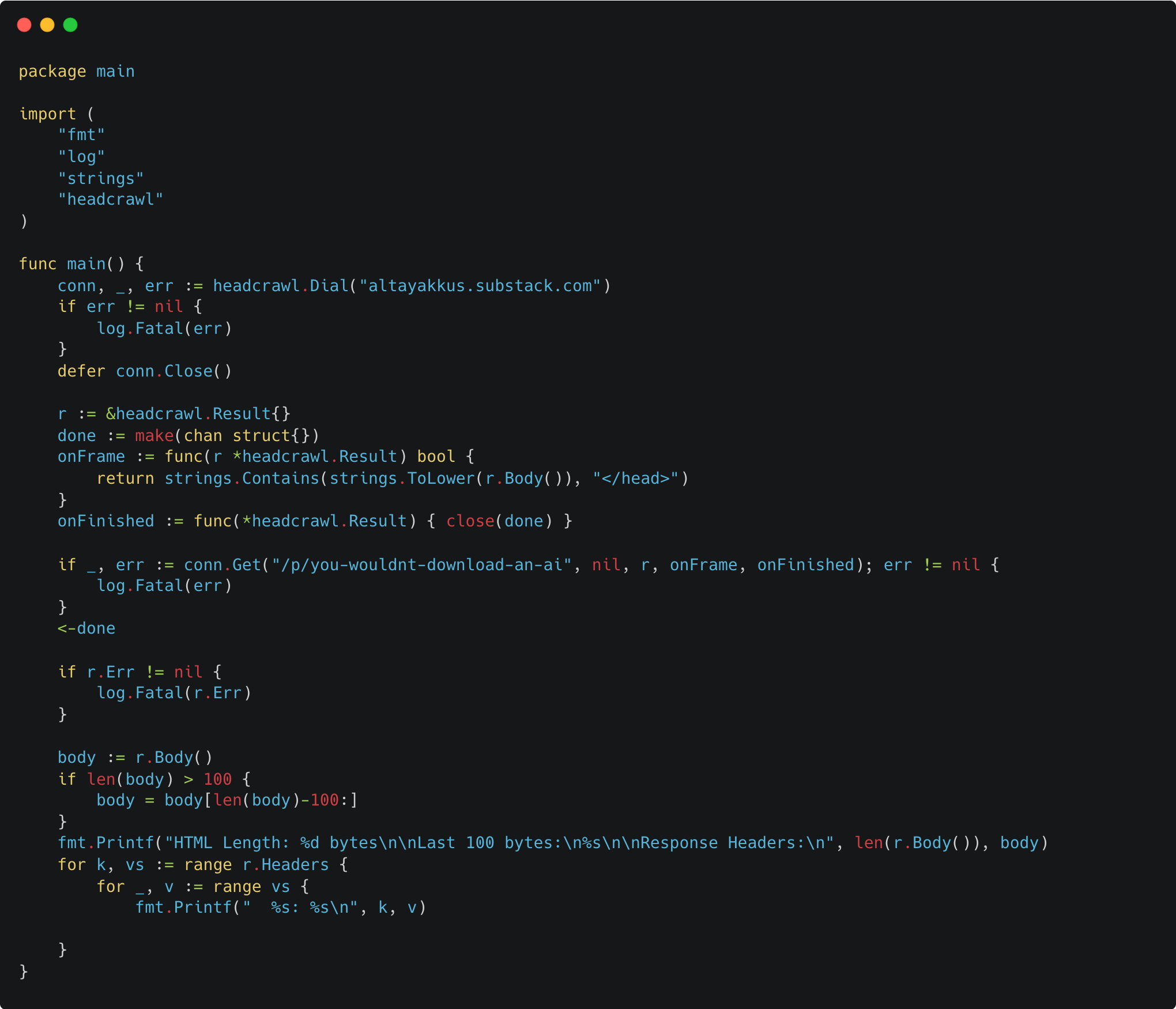
altay@Altays-MBP headcrawl % go run ./cmd/headcrawl
Received frame: type=*http2.WindowUpdateFrame, streamID=0
Received frame: type=*http2.SettingsFrame, streamID=0
Received frame: type=*http2.MetaHeadersFrame, streamID=1
Received frame: type=*http2.DataFrame, streamID=1, size=8186 bytes
Received frame: type=*http2.DataFrame, streamID=1, size=8192 bytes
HTML Length: 16378 bytes
Last 100 bytes:
aws.com%2Fpublic%2Fimages%2F13f918be-3a3b-4cc1-b442-cd912cb5efbe_144x144.png","thumbnailUrl":"https:
Response Headers:
Vary: Accept-Encoding
X-Powered-By: Express
X-Served-By: Substack
...As you can see, the request stops in the middle of the HTML code, shortly after the head section is closed. The head section is within the first 12KB of our document.
There is always going to be some overshoot since the response is fragmented into smaller chunks, but paying for 4KB of useless data is better than paying for 238KB of useless data.
(For serious traffic cheapskates I recommend reading up on RFC9113 (HTTP/2) Section 5.2.1 Flow Control principles. In our WindowUpdateFrame you can force a precise bytes-budget onto the sender. If the HTTP/2 implementers follow RFC2119 this budget MUST be followed.)
I hereby release my low-level HTTP/2 client capable of this into the public domain.
Once I have dealt with off-spec behaviour of HTTP/2 servers (SETTINGS_MAX_CONCURRENT_STREAMS seems to be a recommendation only, the real limit is the grace of our webmasters) and added support for compression (👀) I will release it officially.
