
Timing side-channel on SQL WHERE clauses
Short answer: No.

I am currently developing an application which handles WebRTC video meetings, and the attendees shall be able to gain unauthenticated access to those meetings.
Now these meetings are fairly confidential in nature, so I opted for giving each meeting a unique UUID, and by proving knowledge of this “secret”, the participant shall be able to attend.
CWE-208 and insecure string comparison
There is a fairly known weakness introduced by comparing strings directly with eachother.
The flaw is that comparing two strings is not a constant-time function.
Comparing HalloWelt to HalloWorld takes longer than comparing HalloWelt to Hi.
The reason for this is that these functions typically compare the string byte by byte.

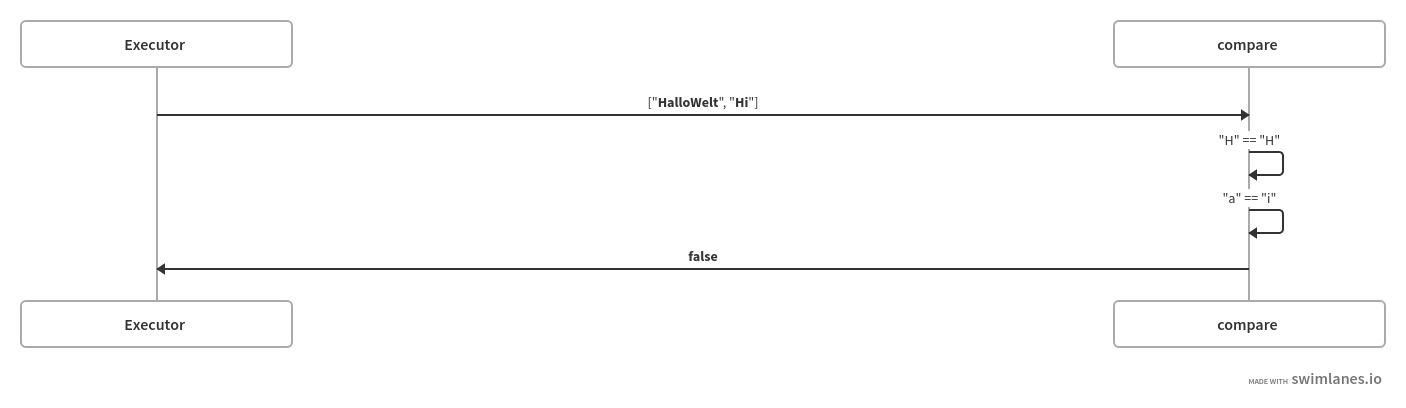
Now it is not very hard to see that the first computation takes more processor cycles (and therefore time) than the second one.
The computation time is dependent on the longest common prefix, so how many starting characters are the same (for HalloWelt and Hi its 1, for HalloWorld and HalloWelt it is 6).
If you, for example, have an embedded device with a bootloader (think U-Boot) you may want to offer a debugging shell, but only to those who know the secret, hardcoded password, you may be tempted to write code like this:
| function unlock(pwd:str) -> bool { | |
| if(pwd == "SUPER_SECURE_PASSWORD_NO_ONE_WILL_GUESS_IT$!") { | |
| elevatedPrivileges = true | |
| return true | |
| } else { | |
| return false | |
| } | |
| } |
This may seem secure at first, because no one will guess “SUPER_SECURE…” but you will have implemented a weakness defined in CWE-208, because “attackers can use timing differences to infer certain properties about a private key, making the key easier to guess.”
Or in simple words: If the command is quick, you are very wrong, if the command is a bit slower, you are less wrong.
Secure String comparison
The recommended way of comparing two strings securely is by using a hash function.
So your compare method actually hashes both strings, and then compares these strings directly with each other.
This has two separate advantages:
Constant length
When you hash your string, it will always have a length of n. For MD5 the resulting hash will be 20 bytes long, whether you pass in “Hi”, “HalloWelt” or a 5 Gigabyte file.
This is important because most string comparison implementations actually check the length of the strings they are loading into memory before actually comparing them.
Because there will be no match between a string thats 8 bytes long and a string which is 5 bytes long, so these “obvious” comparisons will be less computationally expensive.
Avalanche effect
Cryptographic (!) hash functions are designed to have the property of Avalanche effect.
The avalanche effect essentially means that changing the input slightly changes the output significantly.
md5(“Hallo”) → d1bf93299de1b68e6d382c893bf1215f
md5(“Hello”) → 8b1a9953c4611296a827abf8c47804d7
See how a minor change (a → e) provides an entirely different string?
The attacker loses control of the longest common prefix.
Back to the Web
So since I am not working as an embedded developer (unfortunately), my code looks vastly different. I am not actually comparing static strings against user input, and would advise everybody else in my industry to do the same.
We typically performs lookups in a database. An example lookup could look like this:
SELECT * FROM meetings WHERE id=$userInput
Nowadays everybody is using UUIDs instead of auto-incremented integers, since these can be easily guessed, and my use-case would really need a hard-to-guess ID.
And so instead of finally continuing my project I asked myself: Am I introducing a timing side-channel which would allow attackers to more efficiently guess my UUIDs, which provide some sort of authorization?
About timing
In contrast to the U-Boot scenario I showed my web application has more hurdles to gaining the computation time, since we have a lot of intermediaries.

Now one may think that it nearly impossible to extract the comparison/lookup time needed for our attack because the Ingress and Egress Transport time is so dependent on dozens of factors, but this is actually not true.
Closing the gap
Let’s select a random target we may want to do timing analysis on, in our case the website of a german solar company: 1komma5grad.com
We can get the IP address by using Dig, and it is 76.76.21.21 (which is an insanely sexy IP address, btw).
When I ping from my local machine I get responses anywhere from 33ms to 88ms, this is terrible If I want to do timing analysis.
But I can look up which autonomous system this IP is attached to, in order to find out where they are hosting their servers. And it tells me that this IP belongs to Amazon, and that this range is owned by Vercel specifically.
And since AWS is a public-cloud, I can hopefully spin up a machine which is in the same datacenter as my target server.
AWS has regions, which are mostly cities, and availability zones, which are different data centers.
I wanna be as near as possible to my target server, so I will try out all the availability zones.
You can set the availability zone by creating an instance, and explicitly setting the subnet to your desired AZ
AZ A: 1.0ms-1.9ms
AZ B: 0.4ms-0.9ms
AZ C: 1.0ms-1.5ms
So our target server is most likely in the AZ B!
You could even go further, and try to spawn many EC2 machines and benchmark the time, to eventually get placed in the same placement group as your target service, but 0.4ms is enough :)
Please note that I am not actually using this website as a target for any timing analysis.
The only goal of this is to demonstrate that an attacker can easily get near enough to your servers for this attack to be feasible.
If the website uses Cloudflare, like many do, you can by the way try out Cloudflare Workers to get as near as possible :)
Methodology
I wrote a quick Python script which created an SQLite database and a table in it, with an UUID and some Personally identifiable information.
The UUID is then modified to alter the longest common prefix, so if the UUID is a4543… my script tries out
a%%%%
a4%%%
a45%% etc. pp.
And this incrementally matching UUID is then used in a SELECT … WHERE command, and the time to perform that command is saved, together with the index. Each index is tried out 1000 times, so we can filter out one-off delays.

You can look at the code here.
Results
The data clearly shows that the lookup time of a SELECT … WHERE id=$id is not leaking any information about how big longest common prefix is.
See the median and trendline, there is little to no correlation.
SELECT’ing a string which is similiar to the target field will take the same time as SELECT’ing a string that is significantly distinct, so you don’t have to worry about timing side-channels aiding the attacker in (efficiently) guessing your unique string.
Appendix
Remember what I said about comparison algorithms using the size of the data to quickly disregard easy comparisons?
I benchmarked what happens when the database has a field of a fixed-length n, but I try to SELECT with a WHERE equals with a different size m.
The script does not search for the original UUID, but just a random string, increasing it’s size with each iteration.
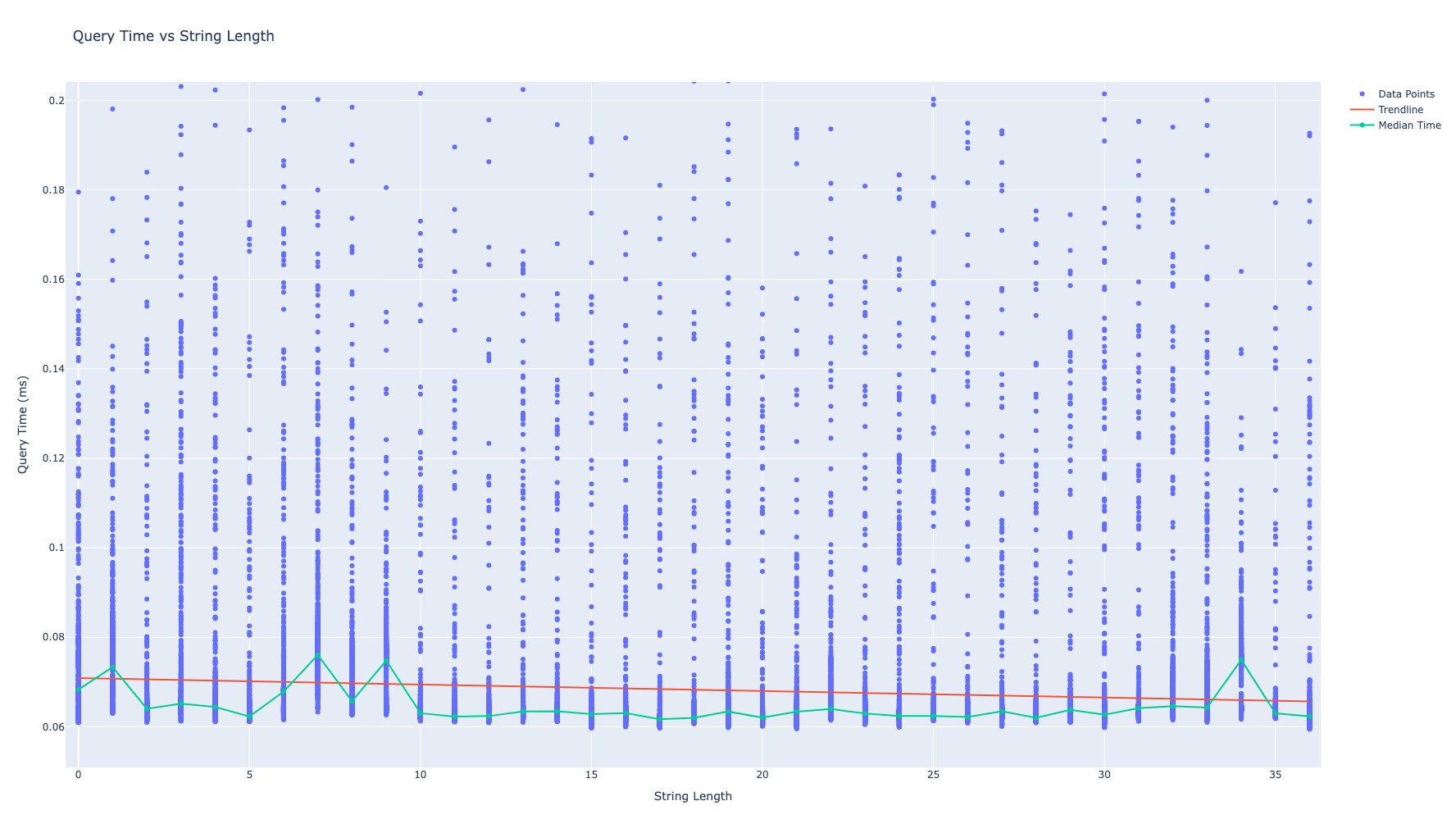
And as you can see, the computation time for the database remains the same, no matter how big the input string is.
So an attacker could also not use timing side-channels to deduct how long a certain field is, e.g. passing in a valid username but increasing the string length to try and get how long the users password is.
PS
SQLite is a fairly simple database, and results MAY be different on PostgreSQL, or MySQL.
If I get sidetracked again maybe I will try again with NoSQL databases. In particular Firebase Firestore is in my interest, because it not only is a NoSQL database, but it is build so users can directly send their requests to the database, with no intermediary application which messes up my timing. And the latency from a GCP compute instance to Firestore should be close to zero, too.